In the world of high-performance systems, data serialization is a critical yet often overlooked aspect. Whether you’re building a real-time multiplayer game, a video streaming service, or a distributed database, how you serialize and deserialize data can make or break your system’s performance. Today, we’ll explore this concept through the lens of a real-time multiplayer game, where every millisecond counts.
The Challenge: Real-Time Multiplayer Games Link to heading
Imagine a fast-paced multiplayer game where player states—position, health, actions, and more—are updated 60 times per second. These updates must be broadcast to all connected clients in near real-time. To handle this, the server often uses an asynchronous architecture, buffering updates in a queue before sending them to clients.
But here’s the catch: if the server uses inefficient serialization methods, it can lead to latency spikes, high CPU usage, and memory bloat. Let’s break down the problem and explore a solution.
The Problem: Inefficient Serialization Link to heading
Traditional Approach (JSON) Link to heading
In a typical setup, the server might process player updates like this:
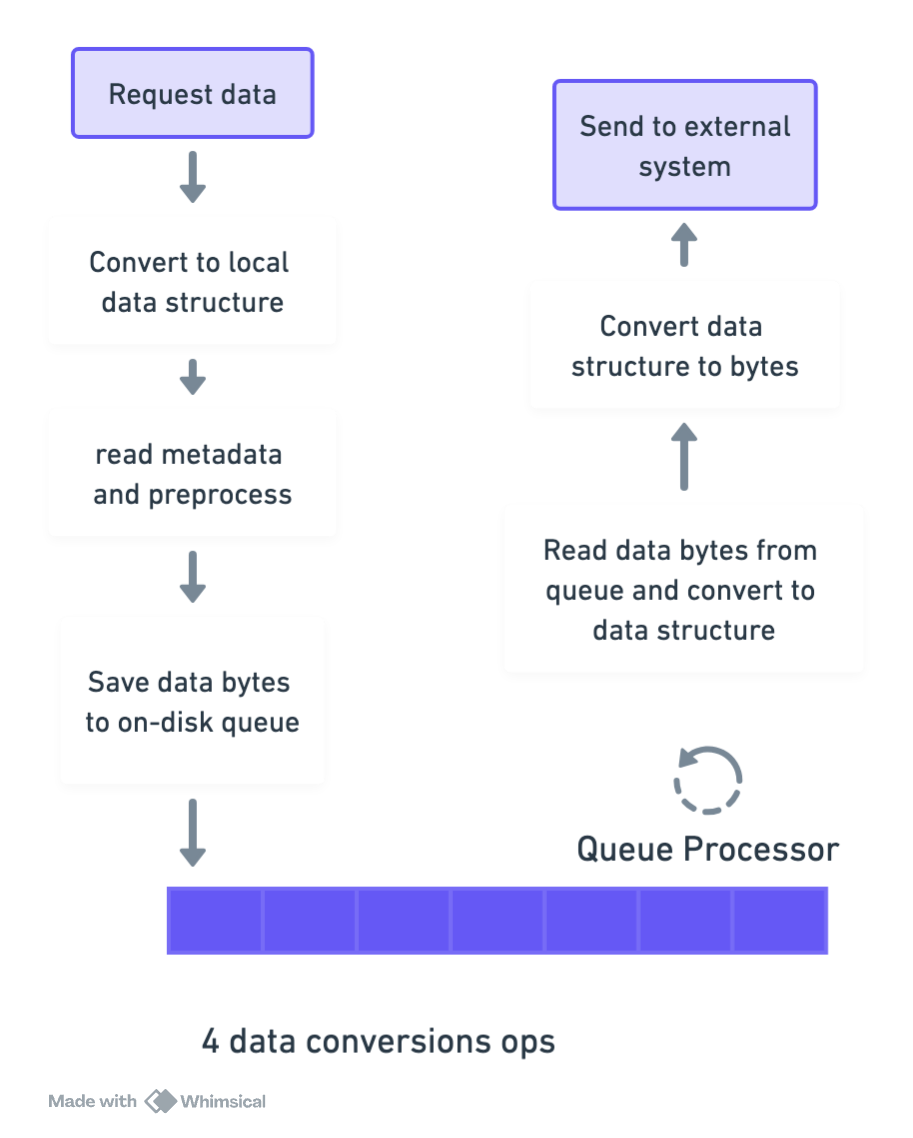
- Deserialize read request metadata for player and game validation
- Serialize player state to JSON bytes for temporary storage in a queue
- Deserialize JSON back to a struct when reading from the queue
- Process the data (ex. validate positions, apply game logic) Reserialize the processed data to JSON for broadcasting to clients
Issues with This Approach Link to heading
- 4 conversions: Deserialize → Serialize → Deserialize → Reserialize
- JSON overhead: Field names like
"position"are repeated in every packet, wasting bandwidth - High CPU usage: Parsing JSON and creating temporary objects strains the CPU
- Garbage collection pressure: Frequent allocations and deallocations slow down the system
The Solution: Custom Binary Serialization Link to heading
To overcome these challenges, we can design a compact binary format that minimizes conversions and memory overhead. Instead of using JSON, we’ll encode player states directly into bytes, avoiding intermediate data structures.
Step 1: Define the Data Structure Link to heading
Let’s start by defining the structure of a player update:
type PlayerUpdate struct {
PlayerID uint32 // 4 bytes
Position [3]int16 // 6 bytes (x, y, z as 16-bit integers)
Health uint8 // 1 byte
Action uint8 // 1 byte (e.g., 0=idle, 1=attacking)
}
// Total size: 12 bytes per update.
This structure is fixed in size, making it easy to encode and decode.
Step 2: Serialize to a Binary Format Link to heading
Instead of JSON, we’ll write raw bytes with a strict layout:
[ PlayerID (4 bytes) | Position (6 bytes) | Health (1 byte) | Action (1 byte) ]
Here’s how we encode the data in Go-like pseudocode:
func (p *PlayerUpdate) Encode() []byte {
buf := make([]byte, 12)
binary.BigEndian.PutUint32(buf[0:4], p.PlayerID)
binary.BigEndian.PutUint16(buf[4:6], uint16(p.Position[0]))
binary.BigEndian.PutUint16(buf[6:8], uint16(p.Position[1]))
binary.BigEndian.PutUint16(buf[8:10], uint16(p.Position[2]))
buf[10] = p.Health
buf[11] = p.Action
return buf
}
Step 3: Asynchronous Flow with Memory Reuse Link to heading
Instead of storing JSON in the queue, we’ll store the raw bytes. Here’s the optimized flow:
Incoming Update → Encode to Binary → Save Bytes to Queue → Read Bytes → Process → Send Bytes to Clients
Key Optimizations Link to heading
- Zero Deserialization: The server processes data directly from the byte stream (e.g., extract
PlayerIDwithout parsing the entire struct). - Memory Pool: Reuse byte buffers to avoid allocations.
var bufferPool = sync.Pool{
New: func() interface{} { return make([]byte, 12) },
}
func EncodeWithPool(p *PlayerUpdate) []byte {
buf := bufferPool.Get().([]byte)
defer bufferPool.Put(buf)
// Write data to buf...
return buf
}
- Batch Updates: Encode multiple player updates into a single packet with headers:
[Header: Packet Size (4B) | Player Count (2B)] → [Player 1 (12B)] → [Player 2 (12B)] → ...
Step 4: Deserialization (Client Side) Link to heading
Clients receive the binary stream and decode it efficiently:
func DecodeBatch(data []byte) []PlayerUpdate {
count := int(binary.BigEndian.Uint16(data[4:6]))
updates := make([]PlayerUpdate, count)
for i := 0; i < count; i++ {
offset := 6 + i*12
updates[i].PlayerID = binary.BigEndian.Uint32(data[offset:offset+4]))
updates[i].Position[0] = int16(binary.BigEndian.Uint16(data[offset+4:offset+6]))
// ... decode other fields
}
return updates
}
Benefits of Binary Serialization Link to heading
- Efficiency: Binary formats are more compact and faster to encode/decode than text-based formats like JSON
- Lower Latency: Faster processing means updates reach clients quicker
- Reduced Disk I/O: Binary data takes up less space, reducing the load on storage systems
Performance Gains Link to heading
| Metric | JSON Approach | Custom Binary |
|---|---|---|
| CPU Usage | High (parsing JSON) | Low (direct byte access) |
| Memory/Update | ~50-100 bytes | 12 bytes |
| Latency | 10-20ms per batch | 1-2ms per batch |
| GC Pressure | High (many allocations) | Near-zero (pooling) |
Key Takeaways Link to heading
- Avoid Intermediate Formats: Skip JSON for internal queues. Use raw bytes with a strict layout
- Memory Pools: Reuse buffers to reduce allocations and GC pressure
- Batch Processing: Encode multiple updates into a single packet to amortize overhead
- Direct Byte Access: Extract fields without full deserialization (e.g., read
PlayerIDdirectly from bytes 0-4)
Conclusion Link to heading
Efficient serialization is the backbone of high-performance systems. By moving away from text-based formats like JSON and embracing custom binary protocols, you can drastically reduce latency, CPU usage, and memory overhead. Whether you’re building a real-time game, a video streaming service, or a distributed database, these principles will help you scale efficiently.